
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- verilog
- Bus
- C++
- 실기
- 정보처리기사
- 코딩테스트
- UNIX
- vitis
- hdl
- amba
- baekjoon
- Zynq
- java
- 정처기
- AMBA BUS
- verilog HDL
- boj
- axi
- 백준
- 자격증
- SQL
- Vivado
- Beakjoon
- 리눅스
- linux
- Xilinx
- FPGA
- Backjoon
- HDLBits
- chip2chip
- Today
- Total
Hueestory
정처기 요약 본문
*잘 외워지지 않거나 중요한 개념만 기출 위주로 정리*
01과목
<애자일 모형>
- 고객의 요구사항 변화에 유연하게 대응할 수 있도록 일정한 주기를 반복하며 개발과정을 진행
- 프로세스와 도구보다는 개인의 상호작용
- 방대한 문서보다는 실행되는 SW
- 계약 협상보다는 고객과 협업
- 계획을 따르기 보다는 변화에 반응
<Scrum; 애자일 모형 기법>
- 팀이 중심이 되어 개발의 효율성을 높인다
- 팀원 스스로가 스크럼 팀을 구성해야 하며, 개발 작업에 대한 모든 것을 스스로 해결 할 수 있어야 한다
- 스크럼 마스터 : 스크럼 프로세스를 따르고, 팀이 스크럼을 효과적으로 활용할 수 있도록 보장하는 역할
- 제품 백로그 : 스크럼 팀이 해결해야 하는 목록으로 소프트웨어 요구사항, 아키텍처 정의 등
- 스프린트 : 하나의 완성된 최종 결과물을 만들기 위해 실제 개발을 2~4주간 진행하는 과정
스프린트 백로그에 작성된 Task를 대상으로 작업 시간을 측정 후 담당 개발자에게 할당
- 속도 : 한 번의 스프린트에서 한 팀이 어느 정도의 제품 백로그를 감당할 수 있는지에 대한 추정치
<디자인 패턴>
- 객체 지향 프로그래밍 설계를 할 때 자주 발생하는 문제들을 피하기 위해 사용되는 패턴
<객체 지향 분석기법>
- Booch(부치) : 미시적·거시적 개발 프로세스를 모두 사용, 클래스·객체들을 분석 및 식별하고 클래스 속성과 연산을 정의
- Rumbaugh(럼바우) : 모든 소프트웨어 구성 요소를 그래픽 표기법을 이용해 모델링, 객체 모형→동적 모형→기능 모형
- Jacobson : 유스케이스를 강조하여 사용
- Wirfs-Brock : 분석과 설계 간의 구분이 없고 고객 명세서를 평가해서 설계 작업까지 연속적으로 수행
<GoF(Gangs of Four) 디자인 패턴>
- 생성 : 추상팩토리, 빌더, 팩토리메서드, 프로토타입, 싱글톤
- 구조 : 어댑터, 브리지, 컴포지트, 데코레이터, 파사드, 플라이웨이트, 프록시
- 행위 : 책임 연쇄, 커맨드, 인터프리터, 중재자, 메멘토, 옵저버, 상태, 전략, 템플릿메서드, 방문자
<UML>
- 시스템 분석, 설계, 구현 등 시스템 개발 과정에서 시스템 개발자와 고객 또는 개발자 상호간의 의사소통을 위해 표준화된 객체지향 모델링 언어
- 정적 다이어그램 : 클래스, 객체, 패키지, 컴포넌트, 복합구조, 배치
- 동적 다이어그램 : 유스케이스, 상태, 활동, 시퀀스, 통신, 상호작용, 타이밍
<아키텍처 설계 과정>
- 설계 목표 설정→시스템 타입 결정→아키텍처 패턴 적용(스타일 적용 및 커스터마이즈)
→서브시스템 구체화(서브시스템의 기능, 인터페이스 동작 작성)→아키텍처 설계 검토
<유스케이스>
- 사용자와 다른 외부 시스템들이 개발될 시스템을 이용해 수행할 수 있는 기능을 사용자의 관점에서 표현
<액터>
- 유스케이스에서 시스템과 상호작용을 하는 요소
- 주액터 : 시스템을 사용함으로써 이득을 얻는 대상
- 부액터 : 주액터의 목적 달성을 위해 시스템에 서비스를 제공하는 외부 시스템
<유스케이스 구성 요소 간의 관계>
- 연관, 집합, 포함, 일반화, 의존, 실체화
<순차 다이어그램>
- 객체 간의 동적 상호작용을 시간 개념을 중심으로 모델링
- 일반적으로 다이어그램의 수직 방향이 시간의 흐름을 나타낸다
- 회귀 메시지, 제어블록 등으로 구성
<MOM>
- 다소 느리고 안정적인 응답을 필요로 할 때 사용
- 독립적인 애플리케이션을 하나의 통합된 시스템으로 묶는 역할
- 송신측과 수신측의 연결 시 메시지 큐를 활용
- 상이한 애플리케이션 간 통신을 비동기 방식으로 지원
<기능적 vs 비기능적 요구사항>
- 기능적 : 시스템이 실제로 어떻게 동작하는지에 관점을 둔 요구사항
- 비기능적 : 실제 수행에 보조적인 요구사항
<UI 설계 도구>
- 스토리보드 : 디자이너와 개발자가 최종적으로 참고하는 작업 지침서
- 목업 : 디자인, 사용방법 설명, 평가 등을 위해 실제와 유사하게 만든 정적인 모형, 구성요소를 배치할 뿐 구현되지는 않음
- 프로토타입 : 실제 구현된 것처럼 테스트가 가능한 동적인 모형
- 유스케이스 : 사용자 측면에서의 요구사항, 사용자의 요구사항을 들어주기 위해 수행할 내용을 기술
<UI의 종류>
- CLI(Command Line Interface) : 텍스트 형태 인터페이스
- GUI(Graphical User Interface) : 그래픽 환경 인터페이스
- NUI(Natural User Interface) : 사용자의 말이나 행동으로 기기를 조작하는 인터페이스
- VUI(Voice User Interface) : 사용자의 음성으로 기기를 조작하는 인터페이스
- OUI(Organic User Interface) : 모든 사물과 사용자 간의 상호작용을 위한 인터페이스
<익스트림 프로그래밍>
- 애자일 방법론 중 하나
- 소규모 개발 조직이 불확실하고 변경이 많은 요구를 접하였을 때 사용
- 수시로 발생하는 고객의 요구사항에 대응하기 위해 고객의 참여와 개발 과정의 반복을 극대화
- 상식적인 원리와 경험을 최대한 끌어올리는 방법
- 구체적인 실천 방법을 정의하고 있으며, 개발 문서 보다는 소스코드에 중점을 둔다
<FEP(Front-End Processor)>
- 입력되는 데이터를 컴퓨터의 프로세스가 처리하기 전에 미리 처리하여 프로세서가 차지하는 시간을 줄여주는 것
<클래스 설계 원칙>
- 단일 책임원칙 : 하나의 객체는 하나의 동작만의 책임을 가진다
- 개방-폐쇄의 원칙 : 클래스는 확장에 대해 열려 있어야 하며 변경에 대해 닫혀 있어야 한다
- 리스코프 교체의 원칙 : 특정 메소드가 상위 타입을 인자로 사용할 때, 그 타입의 하위 타입도 문제 없이 작동해야 한다
- 의존관계 역전의 원칙 : 상위 계층이 하위 계층에 의존하는 관계를 역전하여 상위 계층이 하위 계층의 구현으로부터 독립
02과목
<트리의 운행법>
전위 운행(Pre Order) : Root→Left→Right
중위 운행(In Order) : Left→Root→Right
후위 운행(Post Order) : Left→Right→Root
<배열의 정렬>
- 선택 정렬(Selection Sort) : 배열 내 최소값을 찾은 후 정렬 되지 않은 맨 앞 값과 교환을 하며 정렬하는 알고리즘
- 버블 정렬(Bubble Sort) : 왼쪽부터 두 개씩 비교하여 자리를 바꾸는 정렬 알고리즘
- 삽입 정렬(Insert Sort) : 한 개의 값을 추출한 다음 앞쪽으로 비교해서 본인의 자리에 알맞게 찾아가게 하는 알고리즘
- 퀵 정렬(Quick Sort) : 분할 정복을 기반으로 매우 빠른 수행 속도의 정렬 알고리즘
- 병합 정렬(Quick Sort) : 분할 정복을 기반으로 리스트를 1 이하인 상태까지 절반으로 자른 다음 재귀적으로 합병 정렬을 하는 알고리즘
<JSON>
- 속성-값 쌍으로 이루어진 데이터 오브젝트를 전달하기 위해 사용하는 개방형 표준 포맷
- AJAX에서 많이 사용되고 XML을 대체하는 주요 데이터 포맷이다
- 언어 독립형 데이터 포맷으로 다양한 프로그래밍 언어에서 사용되고 있다
<YAML>
- JSON과 같이 사람이 읽기 쉬운 형태의 데이터 표현 포맷
- XML과 문법적으로 유사하며, 주석을 사용할 수 있고 개행, 공백으로 블록을 인식한다
- 태그를 사용하지 않고 공백 위주로 데이터를 구분하므로 한 줄로 작성할 수 없다
<XML>
- HTML의 단점을 보완하고 SGML의 복잡한 단점을 개선한 특수한 목적을 갖는 마크업 언어
<AJAX>
- 자바스크림트를 사용하여 웹 서버와 클라이언트 간 비동기적으로 XML 데이터를 교환하고 조작하기 위한 웹 기술
<NS Chart>
- 논리의 기술에 중점을 두고 도형을 이용한 표현 방법
- 이해하기 쉽고 코드 변환이 용이하며 연속, 선택, 반복 등의 제어 논리 구조를 표현한다
- 3가지 기본구조만으로 논리를 표현하며 화살표와 GOTO를 사용하지 않는다
<선형 검색 vs 이진 검색>
- 선형 검색 : 검색을 수행하기 전 처음부터 하나씩 순서대로 비교하며 원하는 값을 찾아내는 검색
- 이진 검색 : 검색을 수행하기 전 반드시 데이터의 집합이 정렬되어 있어야 한다
<통합 테스트>
- 시스템을 구성하는 모듈의 인터페이스와 결합을 테스트하는 것
1. 하향식 통합 테스트
- 상위 모듈에서 하위 모듈 방향으로 통합하면서 테스트
- 깊이 우선 통합법, 넓이 우선 통합법 사용
- 테스트 초기부터 사용자에게 시스템 구조를 보여줄 수 있으며, 상위 모듈에는 테스트 케이스를 사용하기 어렵다
2. 상향식 통합 테스트
- 하위 모듈에서 상위 모듈 방향으로 통합하면서 테스트
- 가장 하위 단계의 모듈부터 통합 및 테스트가 수행되므로 스텁(Stub) 대신 클러스터(Cluster)가 필요하다
<테스트 케이스>
- 구현된 소프트웨어가 사용자의 요구사항을 정확하게 준수했는지를 확인하기 위해 설계된 테스트 항목에 대한 명세서
- 테스트 목표와 방법을 설정한 후 주로 시스템 설계 단계에서 작성
- 프로그램에 결함이 있어도 입력에 대해 정상적인 결과를 낼 수 있기 때문에 결함을 검사할 수 있는 테스트 케이스가 필요
- 테스트 오라클 : 테스트 케이스 실행이 통과되었는지를 판단하기 위한 기준
<DRM(Digital Rights Management)>
- 디지털 콘텐츠의 지적 재산권 보호, 관리 기능 및 안전한 유통과 배포를 보장하는 솔루션
- 디지털 콘텐츠와 디바이스의 사용을 제한하기 위해 하드웨어 제조업자, 저작권자 등이 사용하는 접근 제어 기술
- 디지털 미디어의 생명 주기 동안 발생하는 사용 권한 관리, 과금, 유통 단계를 관리한다
- 클리어링 하우스 : 사용자에게 콘텐츠 라이센스를 발급하고 권한을 부여해주는 시스템
<화이트박스 테스트 vs 블랙박스 테스트>
1. 화이트 박스 테스트
- 모듈의 원시 코드를 오픈시킨 상태에서 논리적인 모든 경로를 테스트하여 테스트 케이스를 설계
- 이해를 위해 논리 흐름도를 이용할 수 있다
- 테스트 데이터를 이용해 실제 프로그램을 실행함으로써 오류를 찾는 동적 테스트이다
- 테스트 데이터를 선택하기 위하여 검증기준을 정한다
2. 블랙박스 테스트
- 소프트웨어가 수행할 특정 기능을 알기 위해서 각 기능이 완전히 작동되는 것을 입증하는 테스트
- 프로그램의 구조를 고려하지 않기 때문에 테스트 케이스는 프로그램 또는 모듈의 요구나 명세를 기초로 결정한다
- 소프트웨어 인터페이스에 실시하며, 테스트 과정의 후반부에 적용한다
<워크스루 vs 인스펙션>
- 워크스루 : 요구사항 명세서 작성자를 포함하여 사전 검토한 후 짧은 검토 회의를 통해 결함을 발견
- 인스펙션 : 요구사항 명세서 작성자를 제외한 다른 검토 전문가들이 요구사항 명세서를 확인하면서 결함을 발견
<워크스루의 특성>
- 사용사례를 확장하여 명세하거나 설계 다이어그램, 원시코드, 테스트 케이스 등에 적용할 수 있다
- 복잡한 알고리즘, 반복, 실시간 동작, 병행 처리와 같은 기능이나 동작을 이해하는데에 사용한다
- 단순한 테스트 케이스를 이용하여 프로덕트를 수작업으로 수행해 보는 것이다
<인스펙션 과정>

<RCS(Revision Control System)>
- 다수의 사용자가 동시에 파일 수정을 할 수 없도록 파일 잠금 방식으로 버전을 관리하는 소프트웨어 버전 관리 도구
- 다른 방향으로 진행된 개발 결과를 합치거나 변경 내용을 추적할 수 있다
<RPC(Remote Procedure Call)>
- 별도의 원격 제어를 위한 코딩 없이 다른 주소 공간에서 리모트의 함수나 프로시저를 실행 할 수 있게 해준다
<Refactoring>
- 소프트웨어를 보다 쉽게 이해할 수 있고 적은 비용으로 수정할 수 있도록 외부 동작의 변화 없이 내부구조를 변경
<ISO/IEC 25000>
- 소프트웨어 품질 평가를 위한 소프트웨어 품질평가 통합모델 표준이다
- System and Software Quality Requirements and Evaluation으로 줄여서 SQuaRE라고도 한다
- 기존 소프트웨어 품질 평가 모델과 소프트웨어 평가 절차 모델인 ISO/IEC 9126과 ISO/IEC 14598을 통합했다
<Unit Test>
- 코딩 직후 소프트웨어 설계의 최소 단위인 모듈이나 컴포넌트에 초점을 맞춰 진행하는 테스트
- 구현 단계에서 각 모듈의 개발이 완료된 후 개발자가 명세서의 내용대로 정확히 구현되었는지 테스트한다
- 모듈 내부의 구조를 구체적으로 볼 수 있는 구조적 테스트를 주로 시행한다
- 테스트 드라이버 : 필요 데이터를 인자를 통해 넘겨주고 테스트 완료 후 그 결과값을 받는 역할을 하는 가상의 모듈
- 테스트 스텁 : 인자를 통해 받은 값을 모듈에 넘겨주는 역할
<단위 테스트 도구>
- CppUnit : C++ 프로그래밍 언어용 단위 테스트 도구
- JUnit : 자바 프로그래밍 언어용 단위 테스트 도구
- HttpUnit : 웹 브라우저 없이 웹 사이트 테스트를 수행하는 오픈 소스 소프트웨어 테스트 프레임워크
<소프트웨어 재공학 활동>
- Analysis : 기존 소프트웨어를 분석하여 재공학 대상을 선정하는 것
- Migration : 기존 소프트웨어를 다른 운영체제나 하드웨어 환경에서 사용할 수 있도록 변환하는 작업
- Restructuring : 기존 소프트웨어를 향상시키기 위하여 코드를 재구성하는 작업(기능과 외적 동작은 변함 없음)
- Reverse Engineering : 기존 소프트웨어를 분석하여 소스코드를 얻어내는 작업
03과목
<데이터베이스의 키>
1. 후보키(ex 학번, 주민번호)
- 튜플을 유일하게 식별할 수 있는 속성들의 부분집합
- 모든 릴레이션은 반드시 하나 이상의 후보키를 가진다
- 유일성과 최소성을 만족
2. 기본키(ex 학번)
- 특정 튜플을 유일하게 구별할 수 있는 속성
- NULL 값을 가질 수 없다
- 동일한 값이 중복되어 저장될 수 없다
3. 대체키(=보조키)
- 후보키가 둘 이상일 때 기본키를 제외한 나머지 후보키
4. 슈퍼키
- 한 릴레이션 내에 있는 속성들의 집합으로 구성된 키
- ex) 학번+주민번호, 성명+학번
5. 외래키
- 다른 릴레이션의 기본키를 참조하는 속성
- 릴레이션 간 참조 관계를 표현하는 도구
<무결성>
- 개체 무결성 : 테이블의 기본키를 구성하는 어떤 속성도 NULL값이나 중복값을 가질 수 없다
- 도메인 무결성 : 주어진 속성 값이 정의된 도메인에 속한 값이어야 한다
- 참조 무결성 : 외래키 값은 NULL이거나 참조 릴레이션의 기본키 값과 동일해야 한다
<순수 관계 연산자>
- Select : 선택 조건을 만족하는 튜플의 부분집합을 검색
- Project : 속성 리스트에 제시된 속성 값만을 추출
- Join : 두 개의 릴레이션을 하나로 합침
- Division : 특정 속성은 제외하고 검색
<관계대수 vs 관계해석>
- 관계대수 : 원하는 정보와 그 정보를 검색하기 위해 어떻게 유도하는가를 기술하는 절차적 언어
- 관계해석 : 관계 데이터의 연산을 표현하는 방법으로, 비절차적
<정규화>
- 데이터베이스 내 데이터들의 불필요한 중복을 막기 위함
<정규화 과정>
- 1NF : 도메인이 원자값을 갖도록 테이블 분해
- 2NF : 부분적 함수 종속 제거
- 3NF : 이행적 함수 종속 제거
- BCNF : 결정자이면서 후보키가 아닌 것 제거
- 4NF : 다치 종속 제거
- 5NF : 조인 종속성 이용
<시스템 카탈로그>
- 시스템 그 자체에 관련이 있는 다양한 객체에 관한 정보를 포함하는 시스템 데이터베이스
- 데이터 사전에 저장됨
- 카탈로그에 저장된 정보는 메타 데이터라고 한다
- 일반 사용자도 SQL을 통해 내용을 검색할 수 있다
- INSERT, DELETE, UPDATE 문으로 카탈로그 갱신 불가
- DBMS가 스스로 생성하고 유지한다
- 데이터 디렉토리는 시스템만 접근이 가능하다
<트랜잭션>
- 데이터베이스의 상태를 변환시키기 위해 수행하는 작업의 단위
<트랜잭션의 특성>
- 원자성(Atomicity) : 트랜잭션의 연산은 데이터베이스에 모두 반영되거나 전혀 반영되지 않아야 한다
- 일관성(Consistency) : 트랜잭션이 그 실행을 성공적으로 완료하면 언제나 일관성 있는 데이터베이스 상태로 변환한다
- 독립성(Isolation) : 둘 이상의 트랜잭션이 동시에 병행 실행되는 경우, 다른 트랜잭션의 연산에 끼어들 수 없다
- 영속성(Durability) : 성공적으로 완료된 트랜잭션의 결과는 시스템이 고장나더라도 영구적으로 반영되어야 한다
<뷰>
- 기본 테이블에서 사용자에게 접근이 허용된 자료만 보여주기 위한 가상 테이블
- 물리적으로 존재하지 않고 논리적으로만 존재
- 정의 할 때는 CREATE문, 제거 할 때는 DROP문을 사용하며 ALTER는 사용 불가
<접근 통제 기술>
1. 임의 접근 통제(DAC)
- 데이터에 접근하는 사용자의 신원에 따라 접근 권한을 부여
- 데이터 소유자가 접근통제 권한을 지정하고 제어
- 객체를 생성한 사용자가 객체에 대한 모든 권한을 받고, 다른 사용자에게 권한을 허가할 수 있다
- SQL의 GRANT, REVOKE
2. 강제 접근 통제(MAC)
- 주체와 객체의 등급을 비교하여 접근 권한을 부여
- 시스템이 접근통제 권한을 지정
- 주체는 자신보다 보안 등급이 높은 객체에 대해 읽기, 수정, 등록 불가능
- 보안 등급이 같은 객체에 대해서 읽기, 수정, 등록이 가능
- 보안 등급이 낮은 객체는 읽기만 가능
3. 역할기반 접근통제(RBAC)
- 사용자의 역할에 따라 접근 권한을 부여
- 중앙관리자가 접근 통제 권한을 지정
- 다중 프로그래밍 환경에 최적화
<DDL(데이터 정의어)>
- CREATE : 테이블 생성
- ALTER : 테이블 속성 변경
- DROP : 테이블 제거
<DML(데이터 조작어)>
- SELECT : 테이블에서 조건에 맞는 튜플을 검색
- INSERT : 테이블에 새로운 튜플을 삽입
- DELETE : 테이블에서 조건에 맞는 튜플을 제거
- UPDATE : 테이블에서 조건에 맞는 튜플의 내용을 변경
<DCL(데이터 제어어)>
- COMMIT : 데이터베이스 조작 작업 결과 반영
- ROLLBACK : 원래의 상태로 복구
- GRANT : 데이터베이스 사용자에게 사용 권한을 부여
- REVOKE : 데이터베이스 사용자의 사용 권한을 회수
<트리거>
- 데이터의 삽입, 갱신, 삭제 등의 이벤트가 발생할 때마다 관련 작업이 자동으로 수행되는 절차형 SQL
- 데이터베이스에 저장되며, 데이터 변경 및 무결성 유지, 로그 메시지 출력 등의 목적으로 사용
- 트리거 구문에는 DCL을 사용할 수 없고, DCL이 포함된 프로시저나 함수 호출 시 오류가 발생
04과목
<데이터 크기>
c/c++
- char 1
- unsgined char 1
- short 2
-int 4
- long 4
- longlong 8
- float 4
- double 8
- long double 8
java
- char 2
- byte 1
- short 2
- int 4
- long 8
- float 4
- double 8
- boolean 1
<변수의 규칙>
- 영문, 숫자, 언더바(_) 사용 가능
- 첫 글자에 숫자 사용 불가능
- 공백, *, +, -, / 등 특수문자 사용 불가능
- 대문자와 소문자를 구분한다
- 예약어 사용 불가능
- 데이터 타입을 명시하는 것을 헝가리안 표기법이라고 한다
<while vs do~while>
- while : 조건이 참인 동안 실행할 문장을 반복 수행한다
- do~while : 실행할 문장을 무조건 한 번 실행한 다음 조건을 판단하여 탈출 여부를 결정한다
<break, continue>
- break : switch문이나 반복문에서 사용, break가 나오면 블록을 벗어난다
- continue : 반복문에서만 사용, continue 이후의 문장을 실행하지 않고 반복문의 첫 부분으로 이동한다
<배열 형태의 문자열>
- 배열에 문자열을 저장하면 문자열의 끝을 알리기 위한 NULL('\0')가 문자열 끝에 자동으로 삽입된다
=> NULL문자의 크기까지 고려하여 배열 크기를 지정해야 한다
- 배열에 문자열을 저장할 때는 배열 선언 시 초기값으로 지정해야 하며, 이미 선언된 배열에는 문자열을 저장할 수 없다
<포인터>
- 변수의 주소를 저장할 때 사용
- 포인터 변수를 선언할 때 자료의 형을 먼저 쓰고, 변수명 앞에 간접 연산자 *를 붙인다
- 주소를 저장하게 위해 변수의 주소를 알아낼 때는 변수 앞에 번지 연산자 &를 붙인다
- 실행문에서 *를 붙이면 해당 포인터 변수가 가리키는 곳의 값을 말한다
<Python>
1. 기본 문법
- input() 함수 : 변수 = input(출력문자)
- print() 함수 : print(출력값1, 출력값2, ..., sep = 분리문자, end = 종료문자)
ex) print(82, 24, sep = '-', end = ',') → 82-24,
2. 형변환
- 변환할 데이터가 1개일 때 : 변수 = 변수형(input())
ex) a = int(input()) : input으로 입력받은 값을 정수로 변환하여 변수 a에 저장한다
- 변환할 데이터가 2개 이상일 때 : 변수1, 변수2, ... = map*(변수형, input().split())
ex) a, b = map(int, input().split()) : input().split()으로 입력받은 2개의 값을 정수로 변환하여 변수 a, b에 저장한다
3. List
- C와 Java에서는 여러 요소를 처리할 때 배열을 사용했지만 Python에서는 리스트를 사용한다
- 리스트명 = [값1, 값2, ...] or 리스트명 = list([값1, 값2, ...])
4. Dictionary
- 연관된 값을 묶어서 저장하는 용도
- 사용자가 원하는 값을 키로 지정해 저장된 요소에 접근한다
- 딕셔너리명 = {키1:값1, 키2:값2, ...} or 딕셔너리명 = dict({키1:값1, 키2:값2, ...})
5. Slice
- 문자열이나 리스트 등 순차형 객체에서 일부를 잘라 반환
5.1 정석
- 객체명[초기위치:최종위치] or 객체명[초기위치:최종위치:증가값]
5.2 일부 인수 생략
- 객체명[:] or 객체명[::]
- 객체명[초기위치:] or 객체명[:최종위치] or 객체명[::증가값]
6. if문
- if 조건:\n 실행할 문장
7. for문
- for 변수 in range(최종값):\n 실행할 문장
- for 변수 in 리스트\n 실행할 문장
8. while문
- while 조건:\n 실행할 문장
9. Class
class 클래스명:
실행할 문장
def 메소드명(self, 인수):
실행할 문장
return 값
9.1 클래스 없는 메소드
def 메소드명(인수):
실행할 문장
return 값
<C언어 표준 라이브러리>
- stdio.h : 데이터의 입·출력에 사용되는 기능들을 제공(printf, scanf, fprintf, fscanf, fclose, fopen 등)
- math.h : 수학 함수들을 제공(sqrt, pow, abs 등)
- string.h : 문자열 처리에 사용되는 기능들을 제공(strlen, strcpy, strcmp 등)
- stdlib.h : 자료형 변환, 난수 발생, 메모리 할당에 사용되는 기능들을 제공(atoi, atof, srand, rand, malloc, free 등)
- time.h : 시간 처리에 사용되는 기능들을 제공(time, clock 등)
<UNIX>
- 시분할 시스템을 위해 설계된 대화식 OS, 소스가 공개된 개방형 시스템이다
- C언어로 작성되어 있고 다중 사용자, 다중 작업을 지원한다
- 많은 네트워킹 기능을 제공해 통신망 관리용 OS로 적합
- 트리 구조의 파일 시스템
1. Kernel
- UNIX의 핵심, 컴퓨터가 부팅될 때 주기억장치에 적재된 후 상주하며 실행된다
- 하드웨어의 보호, 프로그램과 하드웨어 간의 인터페이스 역할을 담당
- 프로세스 관리, 기억장치 관리, 파일 관리, 입·출력 관리, 프로세스간 통신, 데이터 전송 및 변환 등의 기능을 제공
2. Shell
- 명령어 해석기, 시스템과 사용자 간의 인터페이스를 담당
- 주기억장치에 상주하지 않고, 명령어가 포함된 파일 형태로 존재하며 보조 기억장치에서 교체 처리가 가능하다
- 파이프라인 기능을 지원하고 입·출력 재지정을 통해 출력과 입력의 방향을 변경할 수 있다
3. Utility Program
- 일반 사용자가 작성한 응용 프로그램을 처리
- DOS의 외부 명령어에 해당
- Editor, Compiler, Interpreter, Debugger 등
<페이징 기법>
- 가상기억장치와 주기억장치의 영역을 동일한 크기로 나눠 나눠진 프로그램을 주기억장치의 동일한 영역에 적재
- 주소 변환을 위해 페이지의 위치 정보를 가지고 있는 페이지 맵 테이블이 필요
- 내부 단편화만 발생
- 페이지 : 프로그램을 일정한 크기로 나눈 단위
- 페이지 프레임 : 페이지 크기로 일정하게 나누어진 주기억장치의 단위
<페이지 크기에 따른 장단점>
1. 페이지 크기가 작을 경우
- 페이지 단편화 감소, 주기억장치로 이동하는 시간 감소
- 불필요한 내용이 주기억장치에 적재될 확률 감소
- Locality에 더 일치할 수 있기 때문에 기억장치 효율 증가
2. 페이지 크기가 클 경우
- 페이지 맵 테이블의 크기 감소, 매핑 속도 증가
- 디스크 접근 횟수의 감소로 전체적인 입·출력 효율 증가
<세그멘테이션 기법>
- 가상기억장치에 보관되어 있는 프로그램을 다양한 크기의 논리적 단위로 나눈 후 주기억장치에 적재
- 외부 단편화만 발생
- 주소 변환을 위해 세그먼트의 위치 정보를 가지고 있는 세그먼트 맵 테이블이 필요
- 세그먼트 : 프로그램을 배열이나 함수 등 논리적 크기로 나눈 단위, 각 세그먼트는 고유한 이름과 크기를 가짐
<페이지 교체 알고리즘>
- 페이지 부재가 발생할 때 가상기억장치의 필요한 페이지를 주기억장치에 적재해야 하는데,
이때 주기억장치의 모든 페이지 프레임이 사용중이면 어떤 페이지 프레임을 선택하여 교체할 것인지를 결정
1. OPT(OPTimal replacement, 최적 교체)
- 앞으로 가장 오랫동안 사용하지 않을 페이지를 교체
- 페이지 부재 횟수가 가장 적게 발생하는 가장 효율적인 알고리즘
2. FIFO(First In Frist Out)
- 가장 먼저 들어온, 가장 오래된 페이지를 교체
- 이해하기 쉽고, 프로그래밍 및 설계가 간단
3. LRU(Least Recently Used)
- 최근에 가장 오랫동안 사용하지 않은 페이지를 교체
- 각 페이지마다 계수기나 스택을 사용해 시간을 측정
4. LFU(Least Frequently Used)
- 사용 빈도가 가장 적은 페이지를 교체
- 활발하게 사용되는 페이지는 교체되지 않음
5. SCR(Second Chance Replacement, 2차 기회 교체)
- 가장 오랫동안 주기억장치에 있던 페이지 중 자주 사용되는 페이지의 교체를 방지
- FIFO 기법의 단점을 보완
6. NUR(Not Used Recently)
- LRU와 유사한, 최근에 사용되지 않은 페이지를 교체
- 최근에 사용되지 않은 페이지는 향후에도 사용되지 않을 가능성이 높다는 것을 전제로, LRU의 시간적 오버헤드 감소
- 최근 사용 여부를 확인하기 위해 각 페이지마다 두 개의 비트(참조 비트, 변형 비트)를 사용
<Process>
- 프로세서(처리기, CPU)에 의해 처리되는 사용자 프로그램, 시스템 프로그램, 즉 실행중인 프로그램을 의미
- 작업(Job), 태스크(Task)라고도 불림
<PCB(Process Control Block)>
- OS가 프로세스에 대한 중요한 정보를 저장해 놓는 곳
- Job Contorl Block, Task Control Block으로도 불림
- 프로세스의 현재 상태, 포인터, 프로세스 고유 식별자, 스케줄링 및 프로세스의 우선순위, CPU 레지스터 정보,
주기억장치 관리 정보, 입·출력 상태 정보, 계정 정보 등이 저장된다
<프로세스 상태 전이>
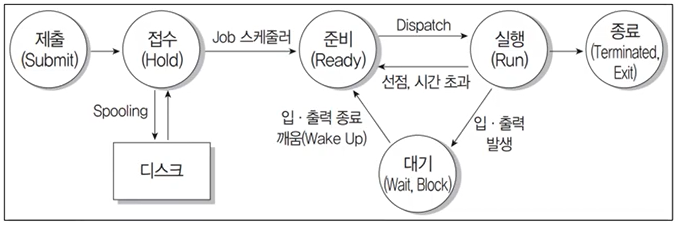
- Dispatch : 준비 상태에서 대기하고 있는 프로세스 중 하나가 프로세서를 할당받아 실행 상태로 전이되는 과정
- Wake Up : 입·출력 작업이 완료되어 프로세스가 대기 상태에서 준비 상태로 전이되는 과정
- Spooling : 입·출력 데이터 를 직접 입·출력 장치에 보내지 않고 나중에 한꺼번에 처리하기 위해 디스크에 저장하는 과정
<Thread>
- 프로세스 내에서의 작업 단위(시스템의 여러 자원을 할당받아 실행하는 프로그램의 단위)
- 단일 스레드와 다중 스레드가 있다
- 스레드 기반 시스템에서 스레드는 독립적인 스케줄링의 최소 단위
- 하나의 프로세스를 여러 개의 스레드로 생성해 병행성을 증진
- HW, OS의 성능과 응용 프로그램의 처리율을 향상
- 응용 프로그램의 응답 시간을 단축
<스케줄링 알고리즘>
1. FCFS(=FIFO, First Come First Service)
- 준비 상대 큐에 도착한 순서대로 CPU를 할당
- 공평성은 유지되지만 짧은 작업이 긴 작업을, 중요한 작업이 중요하지 않은 작업을 기다리게 된다
2. SJF(Shortest Job FIrst)
- 실행 시간이 가장 짧은 프로세스에게 먼저 CPU를 할당
3. HRN(Hightest Response-ratio Next)
- 대기 시간과 서비스 시간을 이용하여 실행 시간이 긴 프로세스에 불리한 SJF 기법을 보완
- (대기 시간+서비스 시간) / 서비스 시간 공식을 사용, 계산 결과가 높은 순으로 우선 순위를 부여
<UNIX/LINUX 환경 변수>
- $DISPLAY : 현재 X 윈도 디스플레이 위치
- $PS1 : 쉘 프롬프트 정보
- $HOME : 사용자의 홈 디렉터리
- $PWD : 현재 작업하는 디렉터리
- $LANG : 프로그램 사용 시 기본적으로 지원되는 언어
<UNIX/LINUX 기본 명령어>
- cat : 파일 내용을 화면에 표시
- chdir : 현재 사용할 디렉터리의 위치를 변경
- chmod : 파일의 보호 모드를 설정하여 파일의 사용 허가를 지정
- chown : 소유자를 변경
- cp : 파일을 복사
- exec : 새로운 프로세스를 수행
- find : 파일을 찾음
- fork : 새로운 프로세스를 생성
- fsck : 파일 시스템을 검사하고 보수
- getpid : 자신의 프로세스 아이디를 얻음
- getppid : 부모 프로세스 아이디를 얻음
- ls : 현재 디렉터리 내의 파일 목록을 확인
- mount/unmount : 파일 시스템을 마운팅/마운팅 해제
- rm : 파일을 삭제
- wait : fork 후 exec에 의해 실행되는 프로세스의 상위 프로세스가 하위 프로세스의 종료 등의 event를 기다림
<IP Address>
- 인터넷에 연결된 모든 컴퓨터 자원을 구분하기 위한 고유한 주소
- 8비트씩 4부분, 총 32비트
- 네트워크 부분의 길이에 따라 A~E 클래스로 구성
<Subnetting>
- 할당된 네트워크 주소를 다시 여러 개의 작은 네트워크로 나누어 사용
- 서브넷 마스크 : 4바이트의 IP 주소 중 네트워크 주소와 호스트 주소를 구분하기 위한 비트
<OSI Model>
- 다른 시스템 간의 원활한 통신을 위해 ISO에서 제안한 Protocol
1. Physical Layer(물리 계층)
- 전송에 필요한 두 장치 간의 실제 접속과 절단 등 기계적, 전기적, 기능적, 절차적 특성에 대한 규칙을 정의
2. Data Link Layer(데이터 링크 계층)
- 두 개의 인접한 개방 시스템들 간의 신뢰성 있고 효율적인 정보 전송을 위해 시스템 간 연결 설정과 유지 및 종료를 담당
- 흐름 제어, 오류 제어(ARQ), 프레임의 동기화
3. Network Layer(네트워크 계층)
- 개방 시스템들 간의 네트워크 연결을 관리하는 기능과 데이터의 교환 및 중계 기능을 함
- 네트워크 연결을 설정, 유지 해제
- 라우팅, 데이터 교환 및 중계, 트래픽 제어, 패킷 정보 전송
4. Transport Layer(전송 계층)
- 종단 시스템(End-to-End) 간 투명한 데이터 전송을 가능하게 함
- 종단 시스템 간의 전송 연결 설정, 데이터 전송, 연결 해제
- 주소 설정, 다중화(En/Decapsulaiton), 오류 제어, 흐름 제어
5. Session Layer(세션 계층)
- 송·수신 측 간의 관련성을 유지하고 대화 제어를 담당
- 대화 구성 및 동기 제어, 데이터 교환 관리
6. Presentation Layer(표현 계층)
- 응용 계층으로부터 받은 데이터를 세션 계층에 보내기 전 통신에 적당한 형태로 변환, 반대 작업도 수행
- 서로 다른 데이터 표현 형태를 갖는 시스템 간의 상호 접속을 제공
- 코드 변환, 데이터 암호화, 데이터 압축, 구문 검색, 정보 형식 변환, 문맥 관리
7. Application Layer(응용 계층)
- 사용자(응용 프로그램)가 OSI 환경에 접근할 수 있도록 서비스를 제공
<네트워크 관련 장비>
- NIC : 컴퓨터와 컴퓨터 또는 컴퓨터와 네트워크를 연결
- Hub : 가까운 거리의 컴퓨터들을 연결
- Repeater : 전송되는 신호가 왜곡되거나 약해질 경우 원래의 신호 형태로 재생하여 다시 전송
- Bridge : LAN과 LAN 또는 LAN 안에서의 컴퓨터 그룹(세그먼트)를 연결, 보안성 증가
- Switch : LAN과 LAN을 연결하여 더 큰 LAN을 만드는 장치, 하드웨어 기반으로 처리하여 전송 속도가 빠름
- Router : LAN과 LAN의 연결 기능에 데이터 전송의 최적 경로를 선택할 수 있는 기능이 추가됨
- Gateway : 전 계층의 프로토콜 구조가 다른 네트워크 연결을 수행, 다른 네트워크와 데이터를 주고 받는 출입구 역할
<응용 계층 프로토콜>
1. FTP(File Transfer Protocol)
- 컴퓨터와 컴퓨터 또는 컴퓨터와 인터넷 사이에서 파일을 주고받을 수 있게 함
2. SMTP(Simple Mail Tranfer Protocol)
- 전자 우편 교환 서비스
3. TELNET
- 멀리 떨어져 있는 컴퓨터에 접속하여 자신의 컴퓨터처럼 사용할 수 있도록 해주는 서비스, Vritual Terminal 역할
4. SNMP(Simple Network Management Protocol)
- TCP/IP의 네트워크 관리 프로토콜
- 네트워크 기기의 네트워크 정보를 네트워크 관리 시스템에 보냄
5. DNS(Domain Name Service)
- 도메인 네임을 IP 주소로 매핑
6. HTTP(HyperText Transfer Protocol)
- WWW에서 HTML 문서를 송·수신 하기 위한 프로토콜
<전송 계층 프로토콜>
1. TCP(Transmission Control Protocol)
- 양방향 연결형(Full Duplex Connection) 서비스를 제공
- 스트림 위주의 전달(패킷 단위)
- 신뢰성 있는 경로를 확립하고 메시지 전송을 감독
- 순서 제어, 오류 제어, 흐름 제어
2. UDP(User Datagram Protocol)
- 데이터 전송 전에 연결을 설정하지 않는 비연결형 서비스를 제공
- TCP에 비해 단순한 헤더 구조, 오버헤드가 적고 흐름제어와 순서제어가 없어 전송 속도가 빠름
- 실시간 전송에 유리, 신뢰성보다는 속도가 중요시되는 네트워크에 사용
3. RTCP(Real-Time Control Protocol)
- RTP(Real-time Transport Protocol) 패킷의 전송 품질을 제어
- 세션에 참여한 각 참여자들에게 주기적으로 제어 정보를 전송
<인터넷 계층 프로토콜>
1. IP(Internet Protocol)
- 전송할 데이터에 주소를 지정하고 경로를 설정
- 비연결형 데이터그램 방식을 사용해 신뢰성이 보장되지 않음
2. ICMP(Internet Control Message Protocol)
- IP와 조합해 통신 중 발생하는 오류의 처리와 전송 경로 변경 등을 위한 제어 메시지를 관리, 헤더는 8byte
3. IGMP(Internet Group Management Protocol)
- 멀티캐스트를 지원하는 호스트나 라우터 사이에서 멀티캐스트 그룹 유지
4. ARP(Address Resolution Protocol)
- 호스트의 IP 주소를 호스트와 연결된 네트워크 접속 장치의 MAC 주소로 변경
5. RARP(Reverse Address Resolution Protocol)
- ARP의 반대, MAC 주소를 IP 주소로 변경
<네트워크 액세스 계층 프로토콜>
1. Etherent
- CSMA/CD 방식의 LAN
2. IEEE 802
- LAN을 위한 표준 프로토콜
3. HDLC
- 비트 위주의 데이터 링크 제어 프로토콜
4. X.25
- 패킷 교환망을 통한 DTE와 DCE 간의 인터페이스를 제공
5. RS-232C
- PTSN을 통한 DTE와 DCE 간의 인터페이스를 제공
05과목
<CASE(Computer Aided Software Engineering)>
- 개발 과정에서 사용되는 요구 분석, 설계, 구현, 검사 및 디버깅 과정 전체 또는 일부를 자동화
- 소프트웨어 생명 주기 전 단계의 연결, 다양한 소프트웨어 개발 모형 지원, 그래픽 지원 등
<LOC(source Line Of Code) 기법>
- 소프트웨어 각 기능의 원시 코드 라인 수의 비관치, 낙관치, 기대치를 측정하여 예측치를 구하고 이를 통해 비용을 산정
- 예측치 = (낙관치 + 기대치*4 + 비관치*4) / 6
<COCOMO(COnstructive COst MOdel) 모형>
- 원시 프로그램의 규모인 LOC에 의한 비용 산정 기법
- 비교적 작은 규모의 프로젝트들을 통계 분석한 결과를 반영한 모델 => 중소 규모 소프트웨어 프로젝트 비용 추정에 적합
1. 조직형(Organic Mode)
- 중·소 규모의 소프트웨어 처리용으로 5만 라인 이하에 사용
2. 반분리형(Semi-Detached Mode)
- 트랜잭션 처리 시스템이나 운영체제, 데이터베이스 관리 시스템 등의 30만 라인 이하에 사용
3. 내장형(Embedded Mode)
- 초대형 규모 트랜잭션 처리 시스템이나 운영체제 등 30만 라인 이상에 사용
<CCMI(Capability Maturity Model Integration, 능력 성숙도 통합 모델)>
- 소프트웨어 개발 조직의 업무 능력 및 조직의 성숙도를 평가
- 초기→관리→정의→정량적 관리→최적화
- 계획단계가 없다
<SPICE(Software Process Improvement and Capability dEtermination)>
- 소프트웨어의품질 및 생산성 향상을 위해 소프트웨어 프로세스를 평가 및 개선
- 불완전→수행→관리→확립→예측→최적화
<테일러링>
- 프로젝트 상황 및 특성에 맞게 정의된 소프트웨어 개발 방법론의 절차, 사용기법 등을 수정 및 보완
- 내부적 기준 : 목표 환경, 요구사항, 프로젝트 규모, 보유 기술
- 외부적 기준 : 법적 제약사항, 국제표준 품질기준
<여러가지 산정 기법>
- Putnam 모형 : 소프트웨어 생명 주기의 전 과정 동안에 사용될 노력의 분포를 가정
- 기능 점수(FP 모형) : 소프트웨어의 기능을 증대시키는 요인별로 가중치를 부여하고, 총 기능 점수를 산출해 비용을 산정
- PERT : 프로젝트 각 작업별로 낙관적인 경우, 가능성이 있는 경우, 비관적인 경우로 나누어 각 단계별 종료 시기를 결정
과거에 경험이 없어 소요 기간 예측이 어려운 소프트웨어에 사용
- CPM : 프로젝트 완성에 필요한 작업을 나열하고 작업에 필요한 소요 기간을 예측
<Framework>
- 소프트웨어 개발에 공통적으로 사용되는 구성 요소와 아키텍처를 일반화하여 손십게 구현할 수 있도록 여러 기능을 제공
- 품질 보증, 개발 용이성, 변경 용이성
- 모듈화 : 캡슐화를 통해 모듈화를 강화하고 설계 및 구현의 변경에 따른 영향을 최소화함으로써 소프트웨어 품질을 향상
- 재사용성 : 재사용 가능한 모듈들을 제공
- 확장성 : 다형성을 통한 인터페이스 확장이 가능
- 제어의 역흐름 : 개발자가 관리하고 통제해야 하는 객체들의 제어를 프레임워크에 넘김
<네트워크 설치 구조>
- 성형(Star) : 중앙 컴퓨터를 중심으로 단말장치들이 연결, Point-to-Point
- 링형(Ring) : 서로 이웃하는 컴퓨터와 단말장치들끼리 Point-to-Point 연결, 하나가 고장나면 네트워크가 먹통이 됨
- 버스형(Bus) : 한 개의 통신 회선에 여러대의 단말장치가 연결, 구조가 간단하며 추가와 제거가 용이, 신뢰성이 높음
- 계층형(Tree) : 중앙 컴퓨터와 일정 지역의 단말장치까지 하나의 통신 회선으로 연결하고, 이웃하는 단말장치는 일정
지역 내에 설치된 중간 단말장치로부터 다시 연결
- 망형(Mesh) : 모든 지점의 컴퓨터와 단말장치를 서로 연결, 많은 양의 통신이 필요한 경우에 유리, 통신 회선이 길다
<CSMA/CA>
- 무선 랜에서 데이터 전송 시 매체가 비어있음을 확인한 뒤 충돌을 피하기 위해 일정한 시간을 기다린 후 데이터를 전송
- 회선을 사용하지 않는 경우에도 확인 신호를 전송하여 동시 전송에 의한 충돌을 예방
<Routing Protocol>
1. 내부 게이트웨이 프로토콜(GP, interior Gateway Protocol)
1.1 RIP(Routing Information Protocol)
- 벨만포드 알고리즘을 사용한 거리 벡터 라우팅 프로토콜
- 최대 홉수를 15로 제한, 소규모 네트워크 환경에 적합
2.1 OSPF(Open Shortest Path First protocol)
- 다익스트라 알고리즘을 사용하여 거리와 링크 상태 정보를 실시간으로 반영하여 라우팅을 지원
- 홉수 제한이 없으며, 라우팅 정보에 변화가 생길 경우 변화된 정보만 네트워크 내의 모든 라우터에 알림
2. EGP(Exterior Gateway Protocol)
- 게이트 웨이 간의 라우팅에 사용되는 프로토콜, 외부 게이트웨이 프로토콜
3. BGP(Border Gateway Protocol)
- EGP의 단점을 보완, 초기 라우터들이 연결될 때에는 라우팅 테이블을 교환하고 이후에는 변화된 정보만을 교환
<Flow Control>
- 네트워크 내의 원활한 흐름을 위해 송·수신 사이에 전송되는 패킷의 양이나 속도를 규제
1. Stop-and-Wait
- 수신 측의 ACK를 받은 후 패킷을 전송
- 한 번에 하나의 패킷만 전송 가능
2. Sliding Window
- ACK를 이용해 송신 데이터의 양을 조절
- ACK를 받지 않아도 미리 정해진 패킷 수 만큼 연속 전송
- Window Size : ACK를 받지 않아도 보낼 수 있는 패킷의 최대치
<SW 관련 용어>
1. Mashup
- 웹에서 제공하는 정보 및 서비스를 이용하여 새로운 소프트웨어나 서비스, 데이터베이스 등을 만드는 기술
2. Digital Twin
- 현실속의 사물을 소프트웨어로 가상화한 모델
<DB 관련 신기술>
1. 하둡(Hadoop)
- 오픈 소스를 기반으로 한 분산 컴퓨팅 플팻폼
- 일반 PC급 컴퓨터들로 가상화된 대형 스토리지를 형성하고 그 안에 보관된 거대한 데이터 세이트를 병렬로 처리
2. 맵리듀스(MapReduce)
- 흩어져 있는 데이터를 연관성 있게 묶는 후 중복 데이터를 제거하고 원하는 데이터를 추출, 대용량 데이터 분산 처리
3. 데이터 마이닝(Data Mining)
- 데이터 웨어하우스에 저장된 데이터 집합에서 사용자의 요구에 따라 유용하고 가능성 있는 정보를 발견
4. OLAP(OnLine Analytical Processing)
- 다차원으로 이루어진 데이터로부터 통계적인 요약 정보를 분석해 의사결정에 활용
<회복(Recovery)>
- 연기 갱신 기법 : 트랜잭션이 성공적으로 완료될 때까지 데이터베이스에 대한 실질적인 갱신을 연기
- 즉각 갱신 기법 : 트랜잭션이 데이터를 갱신하면 트랜잭션이 부분 완료되기 전이라도 즉시 실제 데이터베이스에 반영
- 그림자 페이지 대체 기법 : 데이터베이스를 일정 크기 페이지 단위로 구성하여 복사본을 만들고 장애가 발생하면 대체
- 검사점 기법 : 특정 단계에서 재실행할 수 있도록 정보를 로그에 보관하고 장애가 발생하면 대체
<병행 제어(Concurrency Control)>
- 다중 프로그램의 이점을 활용해 트랜잭션을 병행수행할 때 데이터베이스의 일관성을 파괴하지 않도록 상호 작용을 제어
- 데이터베이스 공유 최대화, 데이터베이스 일관성 유지, 시스템 활용도 최대화, 사용자에 대한 응답시간 최소화
- 미보장시 갱신손실, 현황파악오류, 모순성, 연속성 문제 발생
1. 로킹(Locking)
- 데이터를 잠궈 다른 트랜잭션에서 접근하지 못하도록 한다
- 로킹 단위 : 병행제어에서 한꺼번에 로킹할 수 있는 객체의 크기
=> 데이터베이스, 파일, 레코드, 필드 등이 해당된다
2. 타임 스탬프 순서
- 트랜잭션에 타임 스탬프를 부여해 시간 순서대로 작업을 수행
3. 최적 병행수행
- 판독 전용 트랜잭션이 대부분인 작업은 충돌률이 낮아서 병행제어 기법을 사용하지 않아도 시스템의 상태가 일관성 있게
유지 되는 것을 이용
4. 다중 버전 기법
- 갱신될 때마다의 버전을 부여해 트랜잭션을 관리
<보안 요소>
1. 3대 요소
- 기밀성 : 시스템 내의 정보와 자원은 인가된 사용자에게만 접근이 허용
- 무결성 : 시스템 내의 정보는 오직 인가된 사용자만 수정할 수 있음
- 가용성 : 인가받은 사용자는 언제라도 사용할 수 있음
2. 그 외
- 인증 : 시스템 내의 정보와 자원을 사용하려는 사용자가 합법적인 사용자인지를 확인하는 모든 행위
- 부인 방지 : 데이터를 송·수신한 자가 해당 사실을 부인할 수 없도록 증거를 제공
<접근 지정자>
| 한정자 | 클래스 내부 | 패키지 내부 | 하위 클래스 | 패키지 외부 |
| Public | O | O | O | O |
| Protected | O | O | O | X |
| Default | O | O | X | X |
| Private | O | X | X | X |
<개인키 암호화 vs 공개키 암호화>
1. 개인키 암호화
- 동일한 키로 데이터를 암호화

2. 공개키 암호화
- 암호화할 때 사용하는 공캐키는 데이터베이스 사용자에게 공개하고, 복호화할 때 사용하는 비밀키는 관리자가 관리

<양방향 암호화 알고리즘>
- SEED : 블록 크기는 128비트이며 키 길이에 따라 128, 256로 분류
- ARIA : SEED 이후로 나온 대한민국 국가 암호표준
- DES : 구 미국표준, 블록 크기는 64비트이며 키 길이는 56비트
- AES : DES의 취약점을 보완한 현재 암호표준, 블록 크기는 128비트이며 키 길이에 따라 128, 192, 256로 분류
- RSA : 소인수 분해를 이용, 공개키와 비밀키를 사용
<Hash>
- 임의의 길이의 입력 데이터나 메시지를 고정된 길이의 값이나 키로 변환
- 데이터의 암호화, 무결성 검증을 위해 사용
- 해시 함수 : 해시 알고리즘
- 해시값 : 해시 함수로 변환된 값
- SHA, MD5, N-NASH, SNEFRU 등
<DDoS>
- 여러 곳에 분산된 공격 지점에서 한 곳의 서버에 대한 분산 서비스 공격을 수행
- Trin00, TFN, TFN2K, Stacheldraht 등
<서비스 공격 유형>
- Ping of Death : ping 명령을 전송할 때 인터넷 프로토콜 허용범위 이상의 크기를 가진 패킷을 전송하여 네트워크를 마비
- Smurfing : 엄청난 양의 데이터를 한 사이트에 집중적으로 보내 네트워크를 마비
- Smishing : SMS를 이용해 사용자의 개인 신용정보를 빼냄
- Phishing : 이메일이나 메신저 등을 통해 공기관이나 금융기관을 사칭하여 개인 정보를 빼냄
- Ping Flood : 한 사이트에 많은 ICMP 메시지를 보내 응답으로 시스템 자원을 모두 사용하게 해 네트워크를 마비
- Evil Twin Attack : 실제 존재하는 동일안 이름의 무선 WiFi 신호를 송출하여 로그온한 사람들의 개인 정보를 빼냄
- Swtich Jamming : 위조된 MAC 주소를 네트워크로 계속 흘려보내 스위치 MAC 주소 테이블의 저장 기능을 혼란시킴
<블루투스 관련 공격>
- BlueBug : 블루투스 장비 사이의 취약한 연결 관리를 악용
- BlueSnarf : 블루투스의 취약점을 악용해 장비의 파일에 접근
- BluePrinting : 공격 대상이 될 블루투스 장비를 검색
- BlueJacking : 블루투스를 이용해 스팸 메시지를 익명으로 퍼뜨림
<정보 보안 침해 해킹 공격>
- Worm : 연속적으로 자신을 복제하여 시스템 부하를 높임으로써 시스템을 다운시킴
- Zero Day Attack : 보안 취약점의 존재가 공표되기 전 해당 취약점을 통해 공격
- Key Logger Attack : 사용자의 키보드 움직임을 탐지해 개인 정보를 빼냄
- Ransomware : 인터넷 사용자의 컴퓨터에 잠입해 내부 문서나 파일 등을 암호화하고 돈을 요구
- Back Door(Trap Door) : 설계자가 서비스 기술자의 편의를 위해 보안을 제거하여 만들어놓은 비밀 통로
<인증(Authentication)>
- 다중 사용자 컴퓨터 시스템이나 네트워크 시스템에서 로그인을 요청한 사용자의 정보를 확인하고 접근 권한을 제공
- 지식 기반 인증, 소유 기반 인증, 생체 기반 인증, 위치 기반 인증 등
<침입 탐지 시스템(IDS)>
- 컴퓨터 시스템의 비정상적인 사용, 오용, 남용 등을 실시간으로 탐지
- HIDS(내부) : 내부 시스템의 변화를 실시간으로 감시하여 누가 접근해서 어떤 작업을 수행했는지 기록하고 추적
- NIDS(외부) : 네트워크 트래픽을 감시하여 서비스 거부 공격, 포트 스캔 등의 악의적인 시도를 탐지
<VPN(Virtual Private Network)>
- 사용자가 마치 자신의 전용 회선을 사용하는 것처럼 해주는 가상 사설 네트워크
<SSH(Secure SHell)>
- 다른 컴퓨터에 로그인, 원격 명령, 실행, 파일 복사 등을 수행하게 해줌
'challenge > 정보처리기사 필기(完)' 카테고리의 다른 글
| 정보처리기사 필기 합격 (0) | 2024.08.08 |
|---|---|
| 마무리 요약 (0) | 2024.07.13 |
| 기출 위주 개념 (0) | 2024.07.12 |
| 정처기 기출 (계속 추가) (0) | 2024.07.03 |


